import os # Configure which GPU
if os.getenv("CUDA_VISIBLE_DEVICES") is None:
gpu_num = 0 # Use "" to use the CPU
os.environ["CUDA_VISIBLE_DEVICES"] = f"{gpu_num}"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
# Import Sionna
try:
import sionna as sn
except ImportError as e:
# Install Sionna if package is not already installed
import os
os.system("pip install sionna")
import sionna as sn
# Configure the notebook to use only a single GPU and allocate only as much memory as needed
# For more details, see https://www.tensorflow.org/guide/gpu
import tensorflow as tf
gpus = tf.config.list_physical_devices('GPU')
if gpus:
try:
tf.config.experimental.set_memory_growth(gpus[0], True)
except RuntimeError as e:
print(e)
# Avoid warnings from TensorFlow
tf.get_logger().setLevel('ERROR')
import numpy as np
# For plotting
%matplotlib inline
# also try %matplotlib widget
import matplotlib.pyplot as plt
# for performance measurements
import time
# For the implementation of the Keras models
from tensorflow.keras import ModelSimulate the coded bit error rate (BER) for a Polar coded and 64-QAM modulation. Assume a codeword length of n = 200 and coderate = 0.5.
Hint: For Polar codes, successive cancellation list decoding (SCL) gives the best BER performance. However, successive cancellation (SC) decoding (without a list) is less complex.
n = 200 coderate = 0.5
class MySystemAWGN(Model):
def __init__(self, num_bits_per_symbol, n, coderate):
super().__init__()
self.num_bits_per_symbol = num_bits_per_symbol
self.n = n
if self.n % self.num_bits_per_symbol != 0:
self.n += self.num_bits_per_symbol - self.n % self.num_bits_per_symbol
self.coderate = coderate
self.k = int(n * coderate)
print(self.k)
self.constellation = sn.mapping.Constellation("qam", self.num_bits_per_symbol)
self.mapper = sn.mapping.Mapper(constellation = self.constellation)
self.demapper = sn.mapping.Demapper('app', constellation = self.constellation)
self.binary_source = sn.utils.BinarySource()
self.awgn_channel = sn.channel.AWGN()
self.encoder = sn.fec.polar.Polar5GEncoder(self.k, self.n)
self.decoder = sn.fec.polar.Polar5GDecoder(enc_polar = self.encoder,
dec_type = "SC",
list_size = 8)
def call(self, batch_size, ebno_db):
no = sn.utils.ebnodb2no(ebno_db,
num_bits_per_symbol = self.num_bits_per_symbol,
coderate=1.0)
bits = self.binary_source([batch_size, self.k])
codewords = self.encoder(bits)
# padding
# if codewords.shape[1] % self.num_bits_per_symbol != 0:
# pad = self.num_bits_per_symbol - codewords.shape[1] % self.num_bits_per_symbol
# print(codewords)
# codewords = tf.concat([codewords, tf.zeros([batch_size, pad], dtype=tf.float32)], axis=1)
# print(codewords.shape)
x = self.mapper(codewords)
y = self.awgn_channel([x, no])
llr = self.demapper([y, no])
bits_hat = self.decoder(llr)
return bits, bits_hat
CODERATE = 0.5
BATCH_SIZE = 16
mymodel = MySystemAWGN(num_bits_per_symbol = 6, n = 200, coderate = CODERATE)100
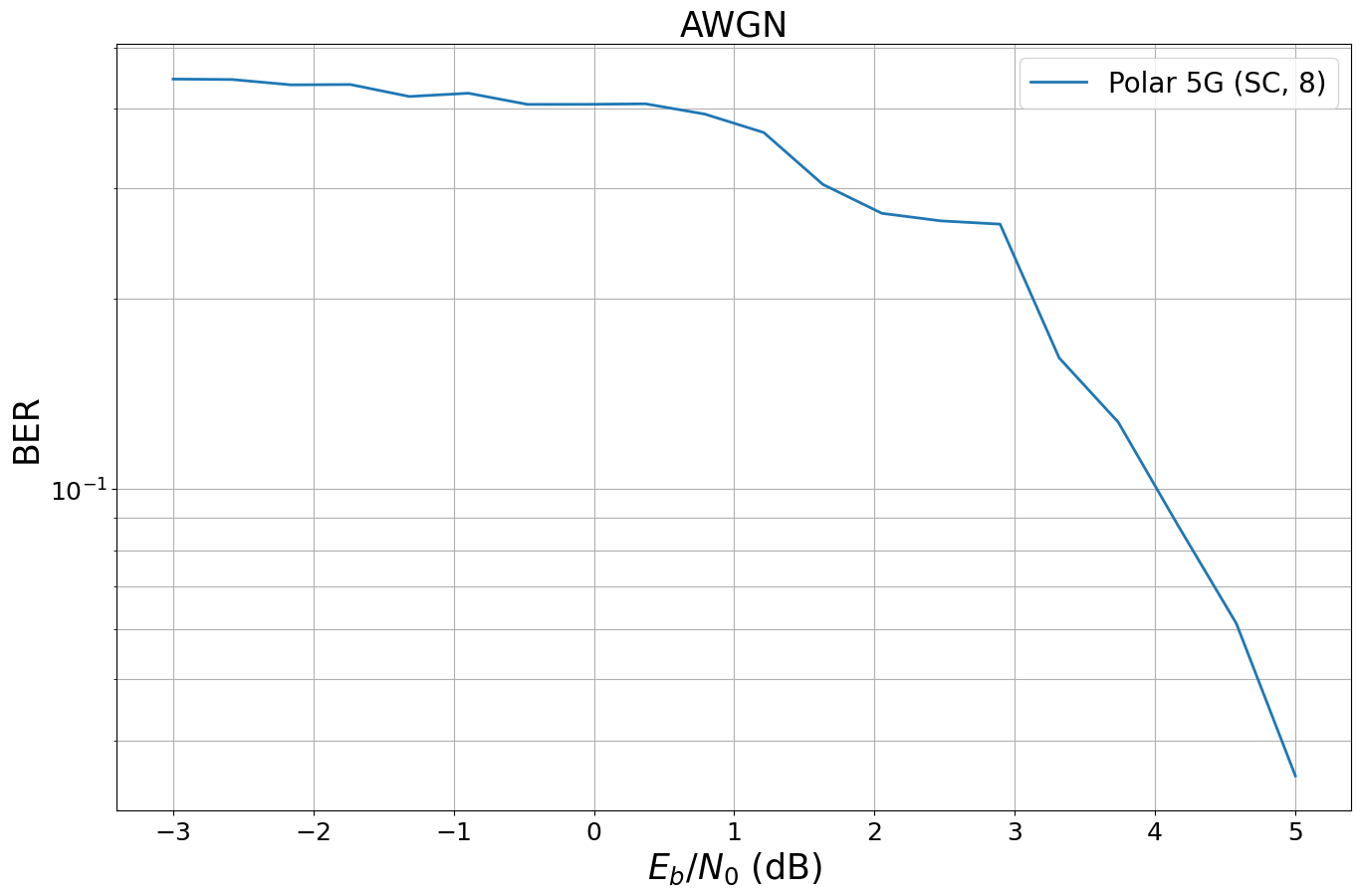
Warning: 5G Polar codes use an integrated CRC that cannot be materialized with SC decoding and, thus, causes a degraded performance. Please consider SCL decoding instead.ber_plots = sn.utils.PlotBER("AWGN")
ber_plots.simulate(mymodel,
ebno_dbs = np.linspace(-3, 5, 20),
batch_size = BATCH_SIZE,
num_target_block_errors = 100,
legend = "Polar 5G (SC, 8)",
soft_estimates = True,
max_mc_iter=100,
show_fig=True)EbNo [dB] | BER | BLER | bit errors | num bits | block errors | num blocks | runtime [s] | status
---------------------------------------------------------------------------------------------------------------------------------------
-3.0 | 4.4571e-01 | 1.0000e+00 | 4992 | 11200 | 112 | 112 | 3.7 |reached target block errors
-2.579 | 4.4500e-01 | 1.0000e+00 | 4984 | 11200 | 112 | 112 | 3.6 |reached target block errors
-2.158 | 4.3643e-01 | 1.0000e+00 | 4888 | 11200 | 112 | 112 | 3.5 |reached target block errors
-1.737 | 4.3696e-01 | 1.0000e+00 | 4894 | 11200 | 112 | 112 | 3.5 |reached target block errors
-1.316 | 4.1830e-01 | 1.0000e+00 | 4685 | 11200 | 112 | 112 | 2.7 |reached target block errors
-0.895 | 4.2330e-01 | 1.0000e+00 | 4741 | 11200 | 112 | 112 | 3.0 |reached target block errors
-0.474 | 4.0643e-01 | 9.9107e-01 | 4552 | 11200 | 111 | 112 | 2.9 |reached target block errors
-0.053 | 4.0652e-01 | 1.0000e+00 | 4553 | 11200 | 112 | 112 | 2.8 |reached target block errors
0.368 | 4.0723e-01 | 9.9107e-01 | 4561 | 11200 | 111 | 112 | 3.6 |reached target block errors
0.789 | 3.9232e-01 | 1.0000e+00 | 4394 | 11200 | 112 | 112 | 3.6 |reached target block errors
1.211 | 3.6679e-01 | 9.8214e-01 | 4108 | 11200 | 110 | 112 | 3.6 |reached target block errors
1.632 | 3.0357e-01 | 9.3750e-01 | 3400 | 11200 | 105 | 112 | 3.6 |reached target block errors
2.053 | 2.7320e-01 | 8.8281e-01 | 3497 | 12800 | 113 | 128 | 4.1 |reached target block errors
2.474 | 2.6578e-01 | 8.7500e-01 | 3402 | 12800 | 112 | 128 | 4.1 |reached target block errors
2.895 | 2.6266e-01 | 8.2031e-01 | 3362 | 12800 | 105 | 128 | 4.1 |reached target block errors
3.316 | 1.6131e-01 | 6.3750e-01 | 2581 | 16000 | 102 | 160 | 5.1 |reached target block errors
3.737 | 1.2761e-01 | 5.6818e-01 | 2246 | 17600 | 100 | 176 | 5.6 |reached target block errors
4.158 | 8.7958e-02 | 4.2083e-01 | 2111 | 24000 | 101 | 240 | 7.7 |reached target block errors
4.579 | 6.1250e-02 | 2.8977e-01 | 2156 | 35200 | 102 | 352 | 11.2 |reached target block errors
5.0 | 3.5133e-02 | 1.9129e-01 | 1855 | 52800 | 101 | 528 | 16.7 |reached target block errors(<tf.Tensor: shape=(20,), dtype=float64, numpy=
array([0.44571429, 0.445 , 0.43642857, 0.43696429, 0.41830357,
0.42330357, 0.40642857, 0.40651786, 0.40723214, 0.39232143,
0.36678571, 0.30357143, 0.27320312, 0.26578125, 0.26265625,
0.1613125 , 0.12761364, 0.08795833, 0.06125 , 0.03513258])>,
<tf.Tensor: shape=(20,), dtype=float64, numpy=
array([1. , 1. , 1. , 1. , 1. ,
1. , 0.99107143, 1. , 0.99107143, 1. ,
0.98214286, 0.9375 , 0.8828125 , 0.875 , 0.8203125 ,
0.6375 , 0.56818182, 0.42083333, 0.28977273, 0.19128788])>)