The mirror descent is an iterative optimization algorithm for finding a local minima of a differentiable function.
1. Preliminaries
1.1. Proximal Gradient Descent
 As a normal gradient descent: \(\eta\nabla f_t(x_t) + (x-x_{t})=0\).
As a normal gradient descent: \(\eta\nabla f_t(x_t) + (x-x_{t})=0\).
\[ x\leftarrow\nabla x_t-\eta\nabla f_t(x_t). \]
Another expression of the proximal gradient descent algorithm is
\[ x_{t+1}\leftarrow \arg\min_x\{f_t(x_t) + \eta\cdot\langle\nabla f_t(x_t),x-x_t\rangle + \frac{1}{2}\Vert x-x_t\Vert^2 \}. \] From the proximal gradient descent, the focus of mirror descent is to replace the squared Euclidean norm by other distances to get different algorithms.
1.2. Bregman Divergences
Given a strictly convex function \(h\), we can define a distance based on how the function differs from its linear approximation.
Definition 1. The bregman divergence from \(x\) to \(y\) with respect to function \(h\) is
\[ D_h(y||x) = h(y) - h(x) - \langle \nabla h(x), y-x \rangle. \]
- \(h(y) - h(x)\) : difference of function outputs from \(x\) to \(y\).
- \(\langle \nabla h(x), y-x \rangle\) : linear approximation.
- For given a convex function \(h\), \(D=0\) iff \(x=y\).
2. Mirror descent
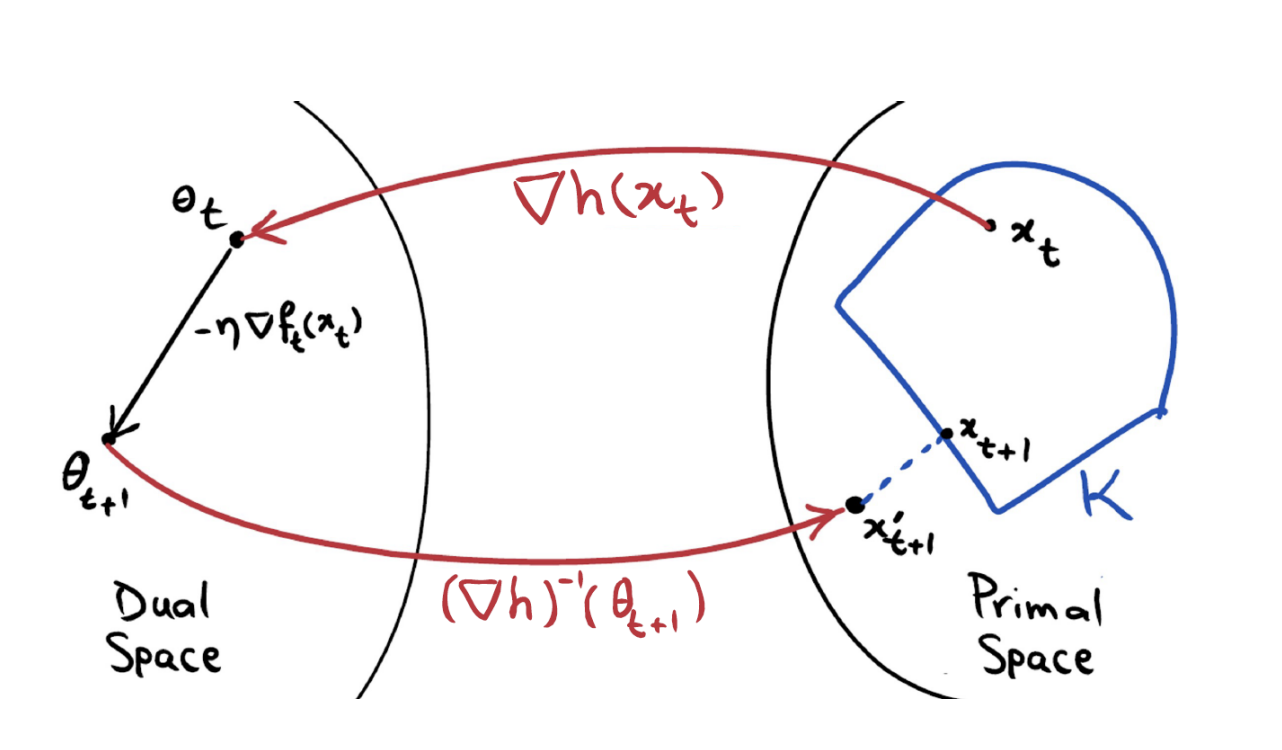
Changing the distance function from Euclidean norm to Bregman divergence
\[ x_{t+1}\leftarrow \arg\min_x \{ \eta\langle\nabla f_t(x_t), x\rangle + D_h(x||x_t) \}. \]
Again, setting the gradient at \(x_{t+1}\) to zero, we have
\[ \eta \nabla f_t(x_t) + \nabla h(x_{t+1}) - \nabla h(x_t) \]
Let us consider a dual space, where \(\theta = \nabla_x h(x)\), and \(x = (\nabla h)^{-1}(\theta)\). Then the above equation can be rewritten as
\[ \theta_{t+1} = \theta_t - \eta\nabla_x f_t(x_t). \]
In the above figure, if the problem is constrained problem, projection the \(x_{t+1}'\) into feasible space \(\mathcal{K}\).
Reference 1. Arkadi Nemirovsky and David Yudin. Problem Complexity and Method Efficiency in Optimization. John Wiley & Sons, 1983 2. https://www.cs.cmu.edu/afs/cs.cmu.edu/academic/class/15850-f20/www/notes/lec19.pdf 3.